RAG’ı Sıfırdan Kodlamak: Qdrant ile Pratik Bir Rehber

RAG, fine-tuning, LlamaIndex gibi n-tane kavramın günlük dile kadar indiği bir ortamdayız. Ama dikkat ettiniz mi herkes bunları birer genel kültür terimi olarak kullanıyor. Yüzeysel olarak ne olduğunu biliyoruz. Ama hiç uygulamadık. Biraz garip değil mi? Hiç bu kavramların üzerinde uygulama yapmadık. Hadi gelin bu sihri bozalım ve biraz işin içine girelim.
Bu RAG Gerçekten Nedir?#
RAG elimizdeki verileri en küçük anlamlı parçalara bölüp bunları semantik vektörlere (ben bu kavramı çok seviyorum, çünkü elimizdeki “embedding model” kavramı pek açıklayıcı değil) çevirip saklıyoruz. Bir filtre girildiğinde bunu da güzel bir vektöre çevirip vektör database’inde arıyoruz ve hop en yakın çözüm anlamsal olarak bize en yakın şeydir diyoruz. Böyle anlatınca iyice karıştı değil mi? Peki sırayla gidelim o zaman.
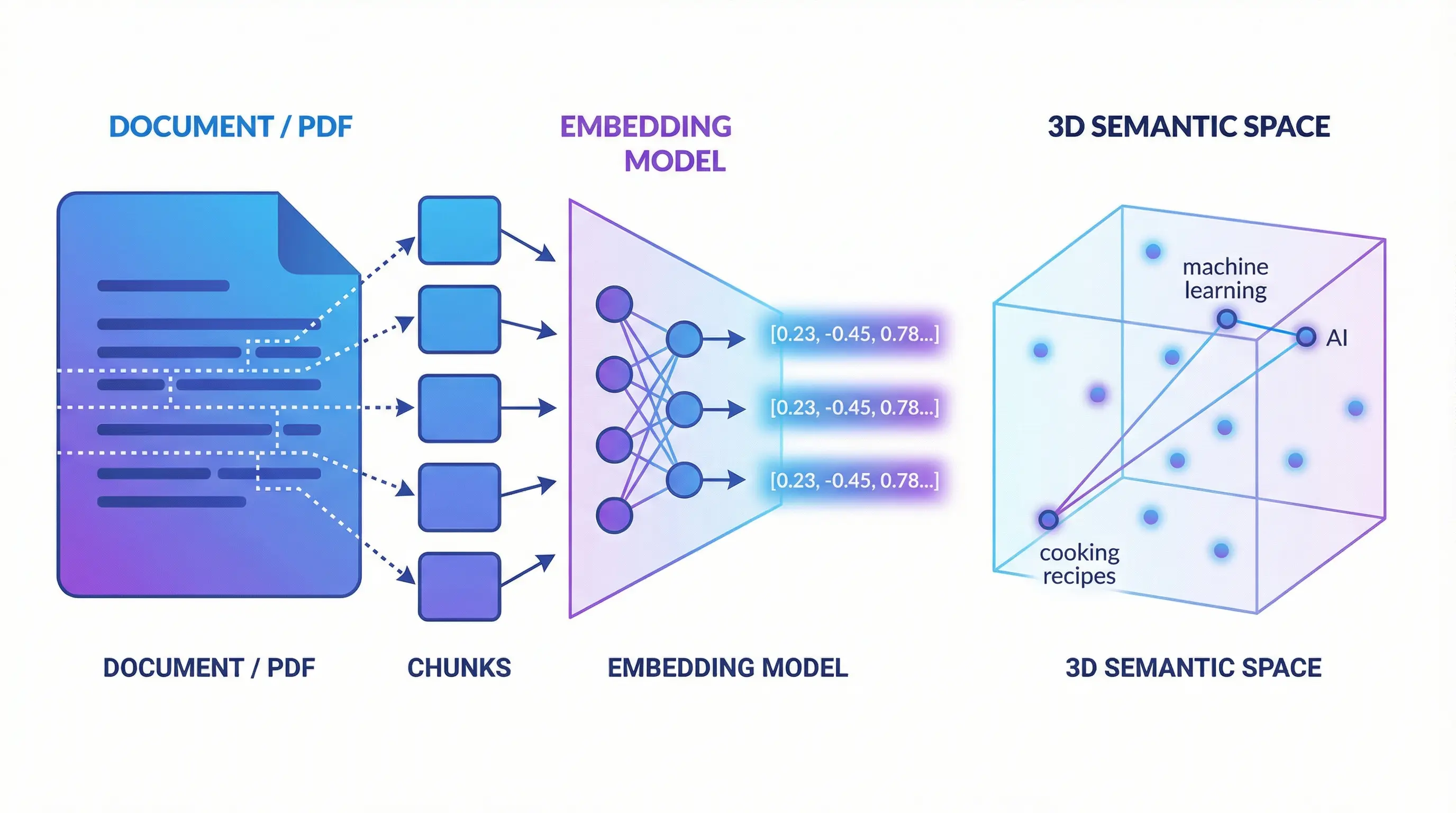
En Küçük Anlamlı Parçaya Kadar Parçalamak#
Elimizde bir doküman var. Bunu anlamlı en küçük parçaya kadar parçalayalım. Neden? Öyle olduğu gibi kalsa olmaz mı? Olmaz. Çünkü biz bu anlamlı parçaları bir yapay zeka modeli ile semantik kodlayıp saklayacağız.
Semantik kodlama ne demek? Anlam yönünden kodlama demek. Yani içerikteki kelimelerin eş anlamlıları, anlam uzayı gibi kavramlarla onu bir anlamlı vektöre çevirmemiz lazım. Bu vektör anlamlı küçük parça haline gelirse yaptığımız arama da o kadar başarılı olacak.
Chunk Boyutu Neden Önemli?#
Chunk boyutunu seçerken bir denge kurmalıyız: çok küçük chunk’lar bağlam kaybına yol açar (bir cümle tek başına anlamsız kalabilir), çok büyük chunk’lar ise gürültü ekler ve arama sonuçlarının kalitesini düşürür. Genellikle 256-512 token arası iyi bir başlangıç noktasıdır.
Ayrıca chunk’lar arasında overlap (örtüşme) kullanmak önemlidir. Örneğin 512 token’lık chunk’lar arasında 50-100 token’lık bir örtüşme, bir cümlenin ortasından bölünmesini önler ve bağlamın korunmasını sağlar.
|
|
Burada görmüş olduğunuz kod docling ile gelen dokümanı n-item haline getiriyor. Bunu yaparken de bir uzunluk veya boşluk gibi karakterler değil, daha akıllı bir bölütleme mekanizması ile yapıyor. Şimdi bir dokümanın n-item halinde parçalı bir dönüşmüş chunk listesine sahibiz.
Şimdi Bu Anlamlı Parçaları Ne Yapacağız?#
Şimdi bu anlamlı parçaları bir LLM modeli ile “encode” edeceğiz. Encode etmek elimizdeki veriyi bir platformun diline dönüştürmek demektir. Bu da tam bu encoding işlemi işte. Biz buna özel olarak vektörleştirmek diyoruz. Çünkü ortaya çıkan şey LLM’in rahat bir şekilde anlayacağı vektörler.
Peki bu vektörleştirmeyi nasıl yapıyoruz? Şöyle:
|
|
Şimdi elimizdeki chunk listesindeki her bir öğeyi embed edip vektöre çevirdik ve chunk içine kaydettik. Artık elimizdeki chunk listesinde embed edilmiş ve vektöre çevrilmiş bu data var. Bu datayı Qdrant gibi bir vektör database’e kaydedebilirsiniz. Gerçi OpenSearch, ChromaDB ya da PostgreSQL içindeki pgvector eklentisini kullanarak da kaydedebilirsiniz. Biz burada örnek olarak Qdrant kullandık.
Kaydettik, Peki Ama Nasıl Arayacağız?#
Yapmış olduğumuz aramalar ancak vektörel uzaklığın hesaplanması ve en yakın vektörlerin dizilmesi şeklinde olacak diyoruz. Teorik olarak böyle. Biraz önce elimizdeki dokümanları küçük parçalara bölüp (chunking), vektöre çevirip bir vektör veritabanına kaydettik.
Ama yaptığımız arama sadece bir yazıdan ibaret. Onu nasıl vektör uzayına çekeceğiz? Aynı yöntemle! Biraz önce küçük parçaları nasıl embedding yöntemi ile vektöre çevirdik, arama sorgularımızı da aynen öyle vektörlere çevireceğiz. Arama işlemini de bu vektöre en yakın vektörler üzerinden yapacağız.
|
|
Burada gelen request üzerindeki query değerini embed edip vektöre çevirip bir vektör uzayı araması yaptırıyoruz. Aslında belli bir limitte en yakın vektör uzaklıklarına göre puanlıyoruz.
Qdrant burada cosine similarity (kosinüs benzerliği) kullanıyor. Normalde en yakın mesafe 0 ve uzak olan n gibi bir sayı iken, Qdrant bunu score diye bir değer ile tam tersi şekilde yapıyor: en alakasız sonuçlar 0’a yaklaşırken, en alakalı sonuçlar 1’e yaklaşıyor.
Sonuç#
Elimizde artık İngilizce olarak çalışabilen ve semantik olarak en yakın sonuçları bulabilen, klasik kelime temelli aramalardan çok daha akıllı bir arama sistemi tasarlamış olduk.
Bu örnekte sentence-transformers/all-MiniLM-L6-v2 modelini kullandık. Bu model şu an sadece İngilizce destekliyor. Türkçe içeriklerle çalışacaksanız paraphrase-multilingual-MiniLM-L12-v2 veya sentence-transformers/LaBSE gibi çok dilli modelleri tercih edebilirsiniz.
Bir sonraki yazıda hybrid search (BM25 + semantic), reranking veya farklı chunking stratejileri gibi konulara bakacağız.
Source: github.com/turkersenturk/qsearch
Yorumlar